An introduction to
Deep learning¶
What is machine learning?¶
- Machine learning (ML) is a techinque which uses computers to discover patterns or information about your data.
- It is a part of the wider field of artificial intelligence
- There are lots of different types of machine learning
Examples of machine learning¶
- Simplest ML algorithm could be a linear regression. It automatically and iteratively looks at your data to calculate the parameters of your $y = mx + c$ curve
- A more advenced technique is K-means clustering. It is a way of finding clusters of points in your data without having to input any explicit labels.
- The most famous is neural networks (NN) which were inspired by the brain and use a directed network of connected neurons to describe features of the data set.
- More recently (since about 2010) deep neural networks (DNN) have become possible, allowing more detailed models of data to be learned starting the modern buzz for deep learning.
What are neural networks¶
Neural networks are a collection of artificial neurons connected together so it's best to start by learning about about neurons.
In nature, a neuron is a cell which has an electrical connection to other neurons. If a charge is felt from 'enough' of the input neurons then the neuron fires and passes a charge to its output. This design and how they are arranged into networks is the direct inspiration for artificial neural networks.
An artificial neuron has multiple inputs and can pass its output to multiple other neurons.
A neuron will calculate its value, $p = \sum_i{x_iw_i}$ where $x_i$ is the input value and $w_i$ is a weight assigned to that connection. This $p$ is then passed through some activation function to determine the output of the neuron.

Networks¶
The inputs to each neurons either come from the outputs of other neurons or are explicit inputs from the user. This allows you to connect together a large network of neurons:
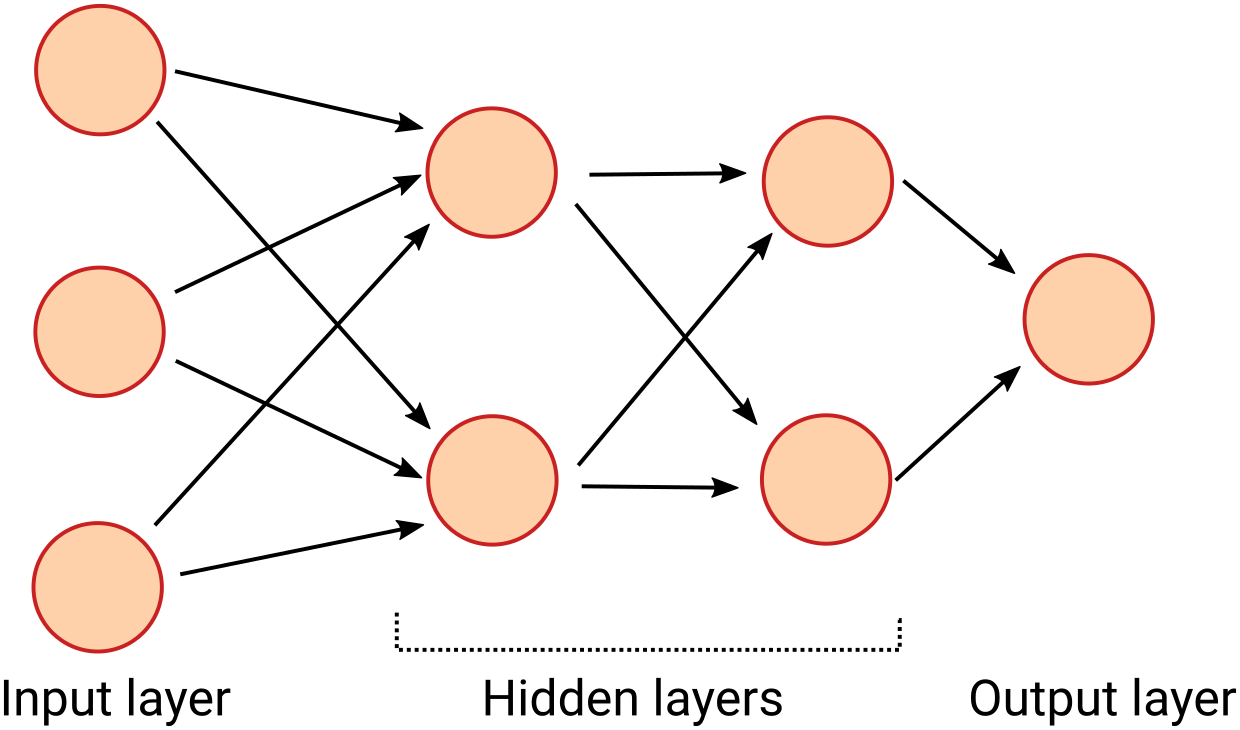
In this network every neuron on one layer is connected to every neuron on the next. Every arrow in the diagram has a weight assigned to it.
You input values on the left-hand side of the network, and the data flows through the network from layer to layer until the output layer has a value.
What shape should the network be?¶
There is some art and some science to deciding the shape of a network. There are rules of thumb (hidden layer size should be similar sized to the input and output layers) but this is one of the things that you need to experiment with and see how it affects performance.
The number of hidden layers relates to the level of abstraction you are looking at. Generally, more complex problems need more hidden layers (i.e. deeper networks) but this makes training harder.
How are the weights calculated?¶
The calculation of the weights in a network is done through a process called training. This generally uses lots of data examples to iteratively work out good values for the weights.
How do you train neural networks¶
The main method by which NNs are trained is a technique called backpropagation.
In order to train your network you need a few things:
- A labelled training data set
- A labelled test (or evaluation) data set
- A set of initial weights
Initial weights¶
The weights to start with are easy: just set them randomly!
Training and testing data sets¶
You will need two data sets. One will be used by the learning algorithm to train the network and the other will be used to report on the quality of the training at the end.
It is important that these data sets are disjoint to prevent overfitting.
It is common to start with one large set of data that you want to learn about and to split it into 80% training data set and 20% test data set.
Backpropagation ("the backward propagation of errors")¶
Once you have your network structure, your initial weights and your training data set, you can start training.
There have been lots of algorithms to do this over the last several decades but the currently most popular one is backpropagation.
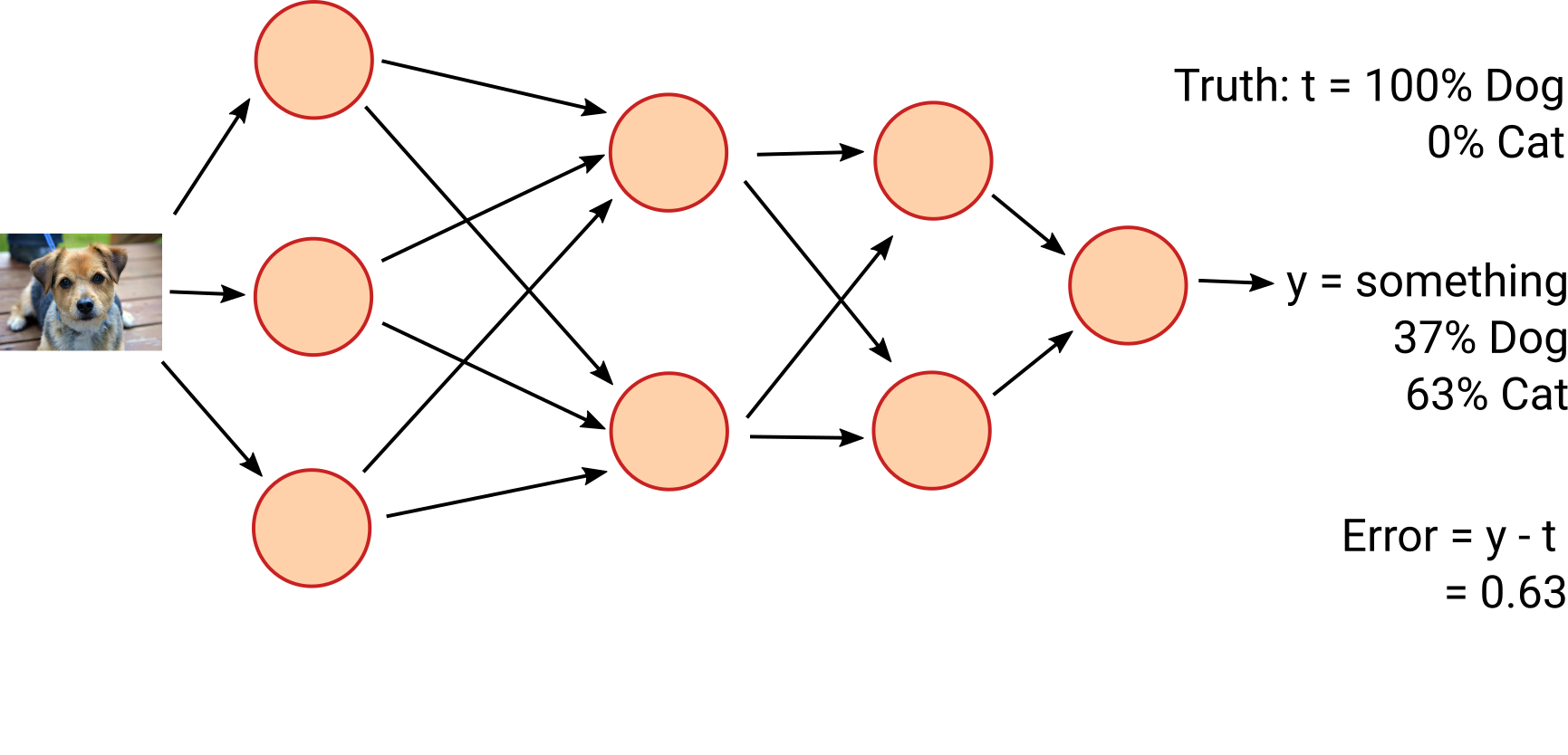
First, we define our loss function, a measure of "how wrong" we are. For example, $J(y) = (t-y)^2$ where $y$ is the output of the network and $t$ is what we want the output to be.
We then calculate its derivative with respect to each weight, $D_n(y) = \frac{dJ(y)}{dw_n}$. This gives how much you need to tweak each weight—and in which direction—to correct the output.
Then for each training entry:
- pass it through the network and find the value $y$
- tweak each weight by $\delta w_n = -R D_n(y)$ where $R$ is the learning rate
This means that the 'more wrong' the weights are, the more they move towards the true value. This slows down as, after lots of examples, the network converges.
Common neural network libraries¶
It would, as with with most things, be possible to to the above by hand but that would take years to make any progress. Instead we use software packages to do the leg work for us.
The can in general, construct networks, automatically calculate derivatives, perform backpropagation and evaluate performance for you.
Some of the most popular are:
- PyTorch
- TensorFlow
- Keras
- Caffe2
- scikit-learn
In this workshop, we will be using TensorFlow with a little bit of Keras.
Our first neural network: classifying Irises¶
We're going to start with a classic machine learning example, classifying species of Irises.

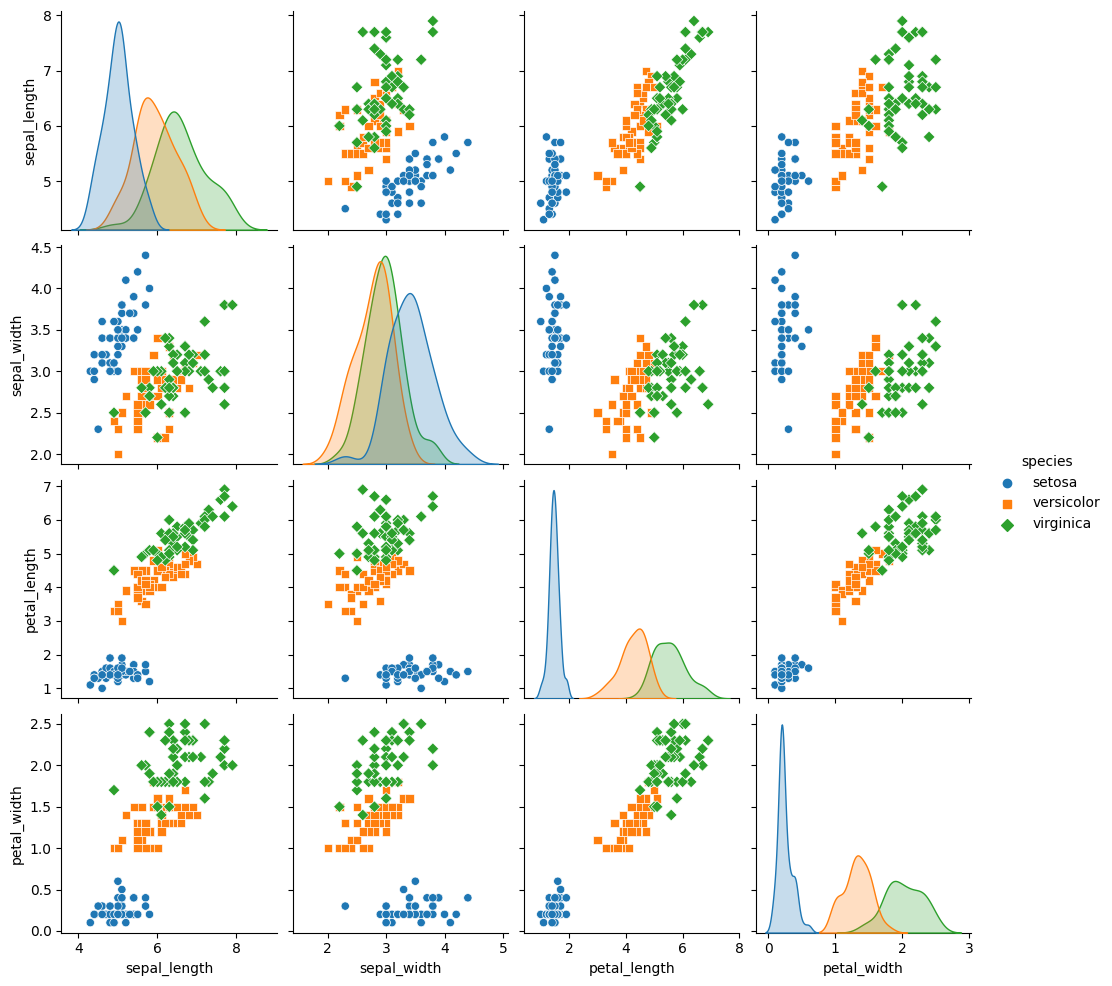
Iris setosa, Iris versicolor, and Iris virginica
Data set¶
There exists a data set of 150 irises, each classified by sepal length and width, and petal length and width.
| Sepal length | sepal width | petal length | petal width | species |
|---|---|---|---|---|
| 6.4 | 2.8 | 5.6 | 2.2 | 2 |
| 5.0 | 2.3 | 3.3 | 1.0 | 1 |
| 0.9 | 2.5 | 4.5 | 1.7 | 2 |
| 4.9 | 3.1 | 1.5 | 0.1 | 0 |
| ... | ... | ... | ... | ... |
Each species label is naturally a string (for example, "setosa"), but machine learning typically relies on numeric values. Therefore, someone mapped each string to a number. Here's the representation scheme:
- 0 represents setosa
- 1 represents versicolor
- 2 represents virginica
The code¶
The Python code that we will be running is available at iris.ipynb. Feel free to follow along with that file but the important parts of the code will be on these slides.
Loading our data¶
We start by loading in our data. To make this easier we use scikit-learn which gives us a load_iris() function.
>>> X = load_iris().data
>>> y = load_iris().target
Splitting it into training and test datasets gives us our data ready to use:
>>> X_train, X_test, y_train, y_test = train_test_split(X, y)
>>> X_train[:3]
array([[4.4, 2.9, 1.4, 0.2],
[6.1, 2.8, 4. , 1.3],
[5.2, 3.4, 1.4, 0.2]])
>>> y_train[:3]
array([0, 1, 0])
>>> X_train.shape
(112, 4)
>>> y_train.shape
(112,)
Prepping our data¶
Once we have our raw data, we need to prepare it to be used by the training algorithm. We have our training examples but we want to show them all to the network, over-and-over-again in random orders to nudge the network towards a solution.
- First it converts the input data format to a TensorFlow
Dataset - Then it makes the dataset repeat forever so we can keep on training from it
- Then we shuffle the examples in batches of 1000 to randomise the learning
- Finally we batch up the examples for consumption by the training
train = tf.data.Dataset.from_tensor_slices((X_train, y_train))
train = train.repeat().shuffle(1000).batch(32)
We do similar to the test data but only convert and batch it:
test = tf.data.Dataset.from_tensor_slices((X_test, y_test)).batch(1)
Designing our network¶
TensorFlow has support for building networks with Keras built-in. This lets you build your network layer-by-layer.
We define that there are 4 input features, then two hidden layer with 10 neurons each and finally an output layer with 3 neurons:
model = tf.keras.Sequential([
tf.keras.Input((4,)),
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(3, activation=tf.nn.softmax)
])
We use softmax on the final layer to give us nice probabilites as the output.
Describing the training¶
Before we can train the model we need to specify some details about how the algorithm should progress.
At each step of the training we need to know "how wrong are we" as a single number. If for example for a given run of the network, the output looks like [0.4, 0.3, 0.3] with a correct label of 0 we need a function to compare them and give us a single "error" (e.g. 1.13).
The loss function describes how wrong we are, the optimizer defines how we reduce that loss. In this case, Adam is a sort of gradient descent.
model.compile(
loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
The metrics are only there to show us information during training to monitor progress.
Training our network¶
To train our network, all we need to do is call the fit method on the model object we just created.
It takes a number of arguments, the most important of which is the data to use to train the model. We can also pass in the data to validate the training against (to avoid overfitting) as well as how many batches define an epoch and how many epochs to do.
model.fit(
train,
validation_data=test,
steps_per_epoch=150,
epochs=10,
)
At this point, TensorFlow will go ahead and train the network, outputting its progress to the screen. It should take a few seconds to run.
Evaluating our model¶
We want to check how good a job the training did so we should look at the output of the fit() function. As well as printing the loss on the training data (which is what it uses to progress) it also prints the loss and accuracy of the test data set.
For example, the last epoch has this (or similar) output:
Epoch 10/10
150/150 [==============================] - 0s 1ms/step
- loss: 0.6478
- accuracy: 0.9744
- val_loss: 0.6343
- val_accuracy: 0.9474telling us that the network classified the test data set with a 94.7% accuracy.
Use the model¶
Finally, we want to use the model to make a prediction about the real world. Given a few examples of irises, we evaluate them using the model and compare the results to what would expect:
predict_true_labels = ["setosa", "versicolor", "virginica"]
predict_X = [
[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1],
]
predictions = model.predict(predict_X)
[load_iris().target_names[p.argmax()] for p in predictions]
giving us
['setosa', 'versicolor', 'virginica']
Note that predict_true_labels is not used in the process at all.
Run it yourself¶
To see all the code and run the training for yourself, go to https://colab.research.google.com/github/milliams/intro_deep_learning/blob/master/iris.ipynb. If you are not already logged in to your Google account then you will see a "Sign in" button in the top-right. Click this and get yourself logged in. Then press the "Connect" button in the top-right which you should see change to a green tick and a RAM/Disk meter.
Then go to "Runtime" at the top of the page and click "Run all". It will ask you to confirm running the untrusted code so if you trust me, click "Run anyway". It will then start running each of the code cells in-turn.
Once it is finished you should see:
✓ Prediction is 'setosa' (97.8%), expected 'setosa'
✓ Prediction is 'versicolor' (86.7%), expected 'versicolor'
✓ Prediction is 'virginica' (80.9%), expected 'virginica'Introduction to image analysis¶
The iris example worked well but the big downside is that it required manual processing of the real-world data before it could be modelled. Someone had to go with a ruler and measure the lengths and widths of each of the flowers. A more common and easily obtainable corpus is images.
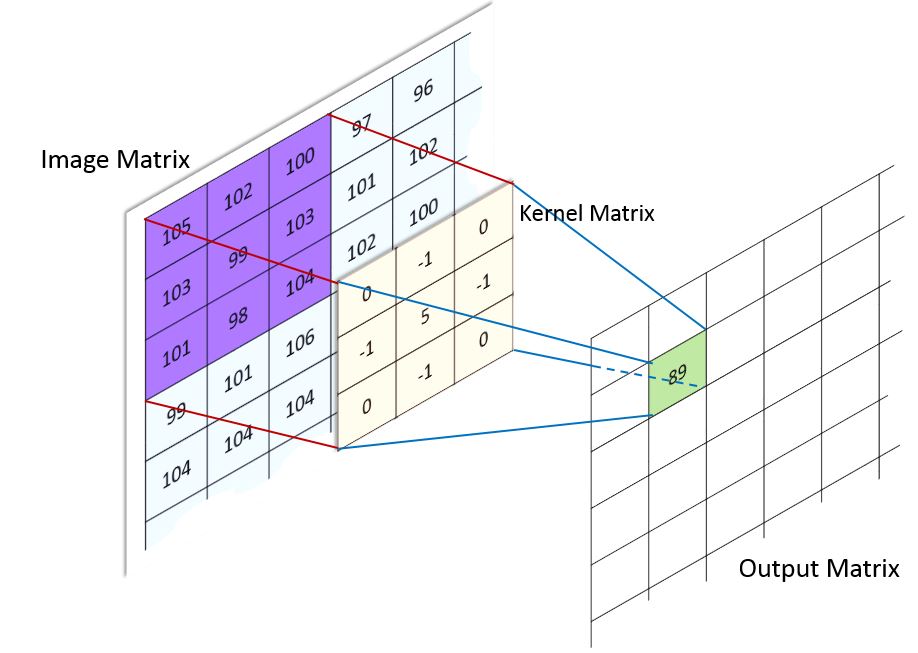
There have been many advancements in image analysis but at the core of most of them is kernel convolution. This starts by treating the image as a grid of numbers, where each number represents the brightness of the pixel
$$ \begin{matrix} 105 & 102 & 100 & 97 & 96 & \dots \\ 103 & 99 & 103 & 101 & 102 & \dots \\ 101 & 98 & 104 & 102 & 100 & \dots \\ 99 & 101 & 106 & 104 & 99 & \dots \\ 104 & 104 & 104 & 100 & 98 & \dots \\ \vdots & \vdots & \vdots & \vdots & \vdots & \ddots \end{matrix} $$Define a kernel¶
You can then create a kernel which defines a filter to be applied to the image:
$$ Kernel = \begin{bmatrix} 0 & -1 & 0 \\ -1 & 5 & -1 \\ 0 & -1 & 0 \end{bmatrix} $$Depending on the values in the kernel, different filtering operations will be performed. The most common are:
- sharpen (shown above)
- blur
- edge detection (directional or isotropic)
The values of the kernels are created by mathematical analysis and are generally fixed. You can see some examples on the Wikipedia page on kernels.
Applying a kernel¶
This kernel is then overlaid over each set of pizels in the image, corresponding values are multiplied and then the total is summed:
First pixel¶
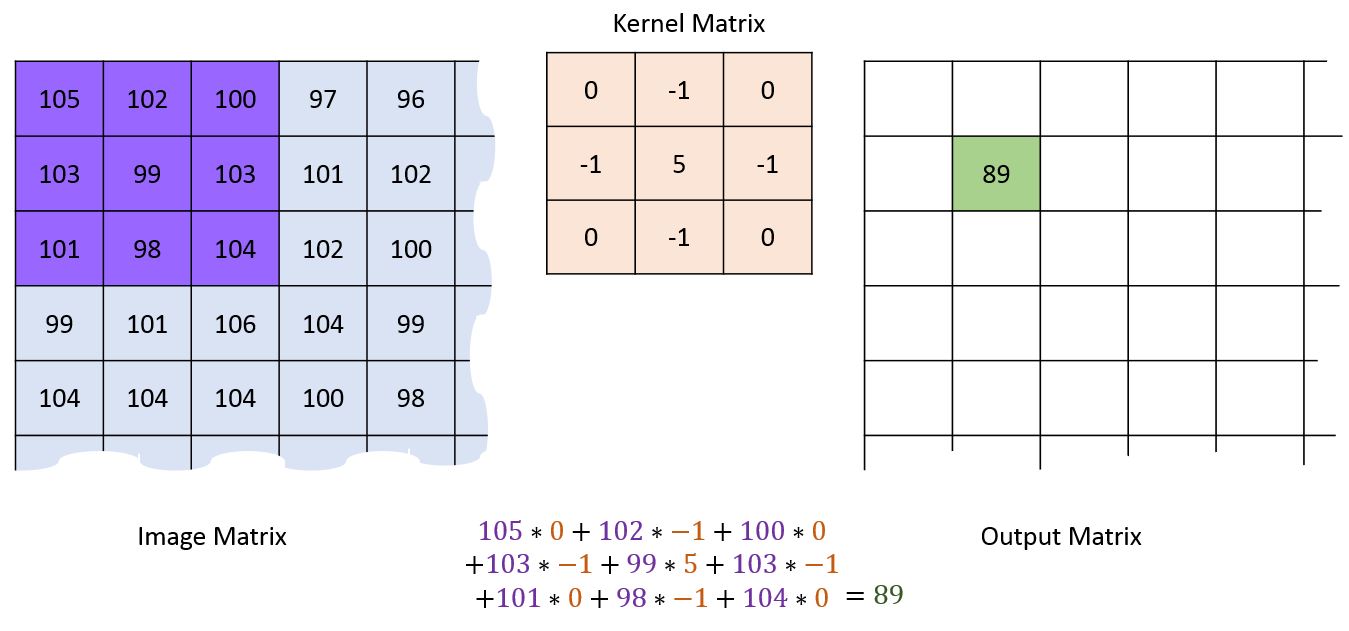
Second pixel¶
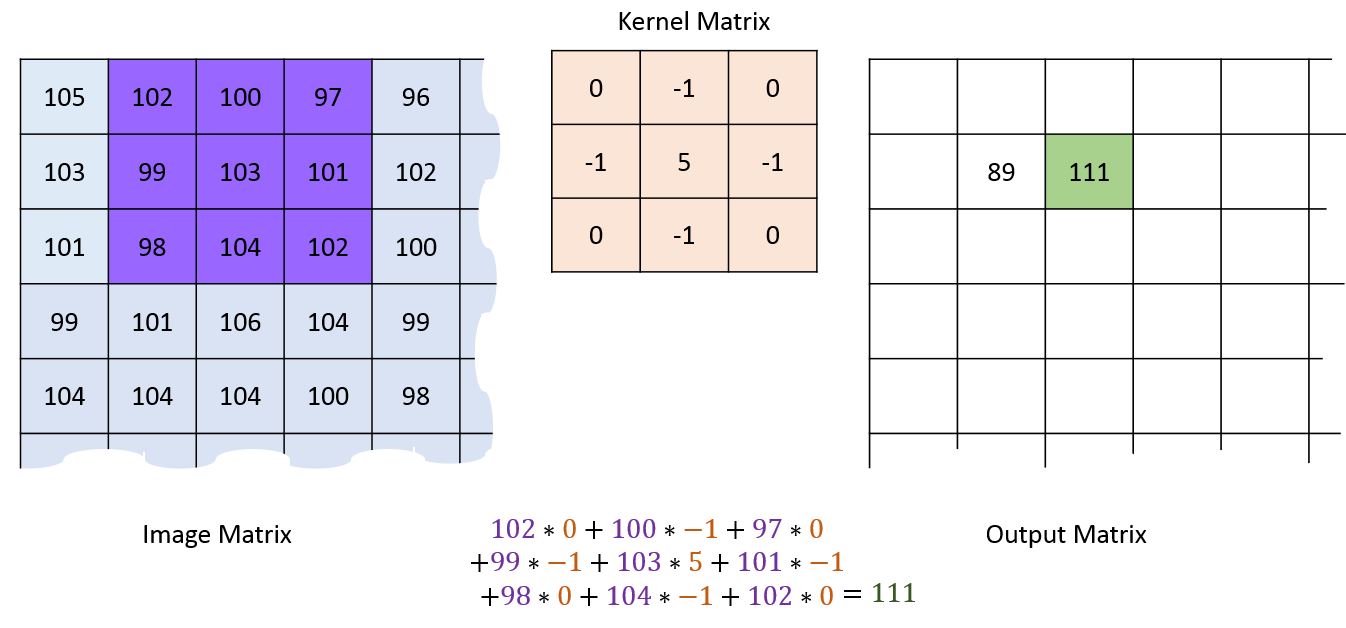
Dealing with edges¶
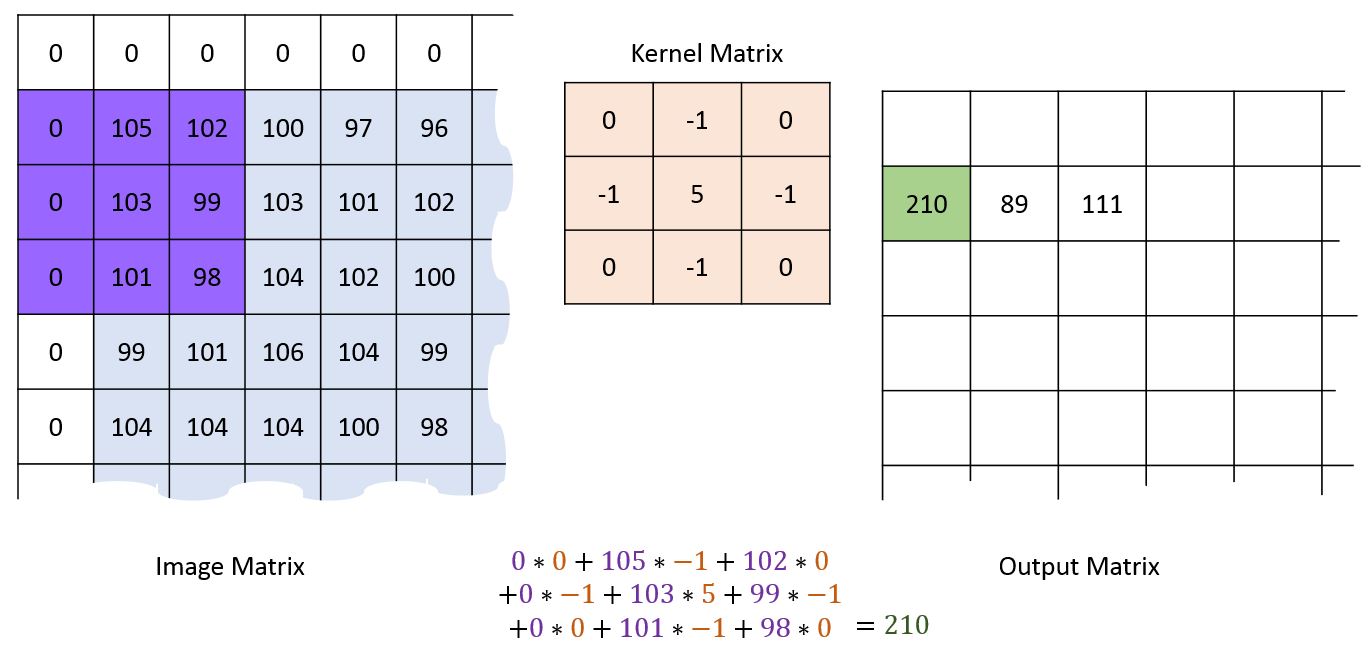

Convolutional neural networks¶
At the core of convolutional neural networks (CNNs) is their ability to create abstract feature detectors automatically. If carefully combined, you can create a network which has layers of abstraction going from "is there an edge here" to "is there an eye here" to "is this a person".
From a neural network perspective, there is little different in training. You can simply treat each element of the convolution kernel as a weight as we did before. The backpropagation algorithm will automatically learn the correct values to describe the training data set.
CNNs apply a series of filters to the raw pixel data of an image to extract and learn higher-level features, which the model can then use for classification. They usually contain three components:
Convolutional layers, which apply a specified number of convolution filters to the image. For each subregion, the layer performs a set of mathematical operations to produce a single value in the output feature map.
Pooling layers, which downsample the image data extracted by the convolutional layers to reduce the dimensionality of the feature map in order to decrease processing time. A commonly used pooling algorithm is max pooling, which extracts subregions of the feature map (e.g., 2x2-pixel tiles), keeps their maximum value, and discards all other values.
Dense (fully connected) layers, which perform classification on the features extracted by the convolutional layers and downsampled by the pooling layers. In a dense layer, every node in the layer is connected to every node in the preceding layer.
Typical CNN¶
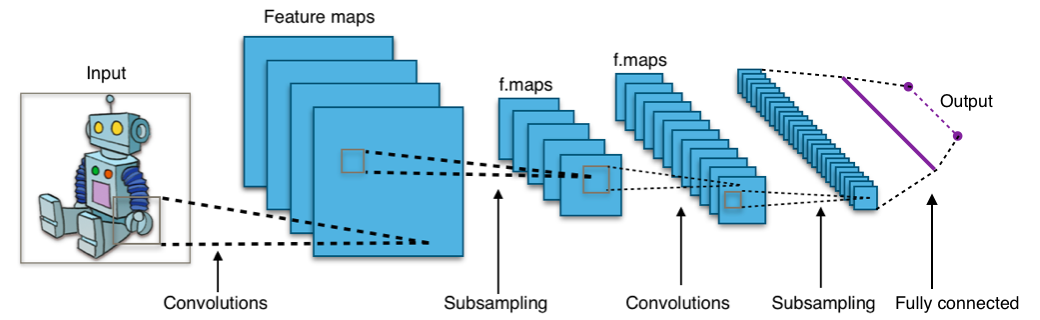
Image segmentation¶

Learn painting styles¶

Nature¶

Handwriting recognition¶
The MNIST data set is a collection of 70,000 28×28 pixel images of scanned, handwritten digits.

We want to create a network which can, given a similar image of a digit, identify its value.
Using TensorFow to create and train a network¶
In TensorFlow, there are three main tasks needed before you can start training. You must:
- Specify the shape of your network
- Specify how the network should be trained
- Specify your training data set
We will now go through each of these to show how the parts fit together.
The code we are using is available at mnist.ipynb so feel free to have a peek but the important bits will be on these slides.
Designing the CNN¶
We will create a network which fits the following design:
- Convolutional Layer #1: Applies 16 5×5 filters (extracting 5×5-pixel subregions), with ReLU activation function
- Pooling Layer #1: Performs max pooling with a 2×2 filter and stride of 2 (which specifies that pooled regions do not overlap)
- Convolutional Layer #2: Applies 32 5×5 filters, with ReLU activation function
- Pooling Layer #2: Again, performs max pooling with a 2×2 filter and stride of 2
- Dense Layer #1: 128 neurons, with dropout regularization rate of 0.4 (probability of 40% that any given element will be dropped during training)
- Dense Layer #2 (Logits Layer): 10 neurons, one for each digit target class (0–9).
This struture has been designed and tweaked specifically for the problem of classifying the MNIST data, however in general it is a good starting point for any similar image classification problem.
Building the CNN¶
We're using TensorFlow to create our CNN but we're able to use the Keras API inside it to simplify the network construction. We build up our network sequentially, layer-by-layer.
First convolutional layer¶
We start with our first convolutional layer. It create 16 5×5 filters. Since we have specified padding="same", the size of the layer will still be 28×28 but as we specified 16 filters, the overall size of the layer will be 28×28×16=12,544.
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(
filters=16,
kernel_size=5,
padding="same",
activation=tf.nn.relu),
])
First pooling layer¶
Next we add in a pooling layer. This reduces the size of the image by a factor of two in each direction (now effectively a 14×14 pixel image). This is important to reduce memory usage and to allow feature generalisation.
max_pool = tf.keras.layers.MaxPool2D((2, 2), (2, 2), padding="same")
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(
filters=16,
kernel_size=5,
padding="same",
activation=tf.nn.relu),
max_pool,
])
After pooling, the layer size is 14×14×16=3136.
Second convolutional and pooling layers¶
We then add in our second convolution and pooling layers which reduce the image size while increasing the width of the network so we can describe more features:
max_pool = tf.keras.layers.MaxPool2D((2, 2), (2, 2), padding="same")
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(
filters=16,
kernel_size=5,
padding="same",
activation=tf.nn.relu),
max_pool,
tf.keras.layers.Conv2D(
filters=32,
kernel_size=5,
padding="same",
activation=tf.nn.relu),
max_pool,
])
After this final convolution and pooling, we have a layer of size 7×7×32=1568.
Fully-connected section¶
Finally, we get to the fully-connected part of the network. At this point we no longer consider this an 'image' any more so we flatten our 3D layer into a linear set of nodes. We then add in a dense (fully-connected) layer with 128 neurons.
To avoid over-fitting, we apply dropout regularization to our dense layer which causes it to randomly ignore 40% of the nodes each training cycle (to help avoid overfitting) before adding in our final layer which has 10 neurons which we expect to relate to each of our 10 classes (the numbers 0-9):
model = tf.keras.models.Sequential([
...
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation="relu"),
tf.keras.layers.Dropout(0.4),
tf.keras.layers.Dense(10, activation="softmax")
])
Telling it how to train¶
To finalise our model we once more use sparse, categorical cross-entropy as the loss function and Adam as the optimiser:
model.compile(
loss="sparse_categorical_crossentropy",
optimizer="adam",
metrics=["accuracy"],
)
Sparse categorical cross-entropy should be used when you have a classification problem and the labels being used are the index of the desired class.
Getting the data into Python¶
We've now finished designing our network so we can start getting our data into place. TensorFlow comes with a built-in loaded for the MNIST dataset which has a pre-configured train/test split:
(ds_train, ds_test), ds_info = tfds.load(
"mnist",
split=["train", "test"],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
ds_train and ds_test are both sequences of 28×28×1 matrices containing the numbers 0-255. Each example also has a label associated with it which is a single integer scalar from 0-9.
Creating the training dataset¶
The first thing we need to do with our data is convert it from being in the range 0-255 to being in the range 0.0-1.0:
def normalize_img(image, label):
return tf.cast(image, tf.float32) / 255., label
ds_train = ds_train.map(normalize_img)
Then we cache the results of this (for speed reasons), shuffle each complete input set and collect them into batches of 128:
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(ds_info.splits["train"].num_examples)
ds_train = ds_train.batch(128)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
.prefetch here is another optimisation to allow it to collect the data for the next epoch while the previous one is running.
Creating the test dataset¶
In order for it to be a fair comparison, we need to do some of the same pre-processing to the test dataset too:
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
Fitting the model to the data¶
At this point, we're all ready to go. We call the fit method on the model, passing in the training data, how long to run for and the test dataset:
model.fit(
ds_train,
epochs=1,
validation_data=ds_test,
)
Run it yourself¶
To run this example, go to https://colab.research.google.com/github/milliams/intro_deep_learning/blob/master/mnist.ipynb
Before running it, go to "Runtime" and "Change runtime type". Under "Hardware accelerator" choose GPU and press "Save".
Then go to "Runtime" at the top of the page and click "Run all". It will ask you to confirm running the untrusted code so if you trust me, click "Run anyway". It will then start running each of the code cells in-turn.
(If you don't set the runtime to GPU, it will still work but will be 10-100 times slower)
Now we wait...¶

Check the output¶
Once it is finished at the end you should see something like:
1 at 0.2%. CNN thinks it's a 3 (38.0%)
2 at 91.2%. CNN thinks it's a 2 (91.2%)
3 at 57.6%. CNN thinks it's a 3 (57.6%)
4 at 0.0%. CNN thinks it's a 3 (99.1%)
5 at 99.9%. CNN thinks it's a 5 (99.9%)
6 at 1.3%. CNN thinks it's a 5 (49.9%)
7 at 65.4%. CNN thinks it's a 7 (65.4%)
8 at 3.9%. CNN thinks it's a 3 (48.6%)
9 at 0.6%. CNN thinks it's a 8 (40.7%)
dog. CNN thinks it's a 2 (50.6%)Or, in a more useful table form...




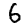
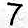



2 and 5 seem to have worked well and 3 and 7 have the correct answer with a low probability but the rest are struggling.
Your results will likely be different but they will probably have the same strengths and weaknesses.
Data augmentation¶
The problem we're seeing here is caused by our training set being a bit restrictive. The network can only learn from what we show it, so if we want it to be able to understand black-on-white writing as well as white-on-black then we need to show it some labelled examples of that too.
If you're training your network to recognise dogs then you don't just want good-looking, well-lit photos of dogs straight on. You want to be able to recognise a variety of angles, lighting conditions, framings etc. Some of these can only be improved by supplying a wider range of input (e.g. by taking new photos) but you can go a long way to improving your resiliency to test data by automatically creating new examples by inverting, blurring, rotating, adding noise, scaling etc. your training data. This is known as data augmentation.
In general, data augmentation is an important part of training any network but it is particularly useful for CNNs.
Inverting the images¶
In our case we're going to simply add colour-inverted versions of the data to our training data set.
We use the Dataset.map() and Dataset.concatenate() methods to double up our training set with a set of images where all the values have been inverted in the range 0-1.
def invert(image, label):
return (tf.cast(image, tf.float32) * -1.0) + 1.0, label
inverted = ds_train.map(invert)
ds_train = ds_train.concatenate(inverted)
This is done after the normalisation but before any of the caching or batching and is done to both the training and the test data sets.
Run it again¶
Go back to the Colab page for mnist.ipynb and this time change the code in the first cell from:
INVERT = False
to
INVERT = True
and redo the "Runtime" → "Run all".
Check the output when it is done and you should see a significant improvement.
Summary¶
It's possible that you only see a small improvement and even a worsening on some examples. Particularly on the 9 example, the network will struggle as it doesn't really represent the training data set. Here are some things that may improve network performance:
- More data augmentation (brightness, rotations, blurring etc.)
- Larger base training set (colour images perhaps)
- Larger number of training epochs (in general, the more the better)
- Tweak the hyperparameters (dropout rate, learning rate, kernel size, number of filters, etc.)
Ethics of machine learning¶
Machine learning has the problem that it can appear to be a bit of a 'black box' when processing information. You put in your question and you get out an answer. The answer isn't necessarilly correct and if you ask a stupid question (like "what handwritten digit is this dog?") you will still get an answer.
Machine learning techniques are becoming more of a part of our daily lives, used by companies to make decisions but with no human in the loop, it can be hard to challenge. Google have a set of AI principles they work towards which I recommend reading but boil down to:
- Be socially beneficial.
- Avoid creating or reinforcing unfair bias.
- Be built and tested for safety.
- Be accountable to people.
- Incorporate privacy design principles.
- Uphold high standards of scientific excellence.
Credits:
- Dog photo: CC BY 2.0 Emily Mathews
- Irises: Iris setosa (by Radomil, CC BY-SA 3.0), Iris versicolor (by Dlanglois, CC BY-SA 3.0), and Iris virginica (by Frank Mayfield, CC BY-SA 2.0).
- Kernel convolution images: http://machinelearninguru.com/computer_vision/basics/convolution/image_convolution_1.html
- CNN layout: CC BY-SA 4.0 Aphex34
- XKCD Compiling comic: CC BY-NC 2.5 Randall Munroe
- Image segmentation: Copyright Mapillary
- Deep painterly: Fujun Luan
{kind=link}