Applied Data Analysis in Python
Clustering¶
Clustering is a process by which you collect a large number of data points into a smaller number of groups, based on the distances between them. It is useful in cases where the volumes of data are large and you want to extract some figures of interest. It is a type of unsupervised learning.
A common use for clustering is identifying distinct subsets of a population, e.g. in a census.
There are a number of algorithms available for performing clustering but the simplest and most common is k-means clustering.
It works by taking the n-dimensional data provided, $X$ and randomly places $k$ seed points in the field which represent the centres of the initial clusters.
- It then iterates over every data point in $X$ and assigns each to be associated with whichever cluster centre is closest.
- Once all points have been associated with a cluster, it then iterates over each cluster and calculates the new mean of the cluster to be the centroid of all the points assigned to it.
Steps 1 and 2 are repeated until the algorithm converges on a result.

A simple example¶
Let's start by using scikit-learn to provide us with some randonly generated data points. It provides a function called make_blobs() which creates a number of gaussian clusters.
We'll ask it to create 500 points in 4 clusters. We set random_state=6 to ensure that this example will always generate the same points for reproducibility.
from sklearn.datasets import make_blobs
data, true_labels = make_blobs(n_samples=500, centers=4, random_state=6)
We then put the data into a pandas DataFrame to give us a nicer API for working with it. We plot it to see what it looks like, colouring each point according to what cluster is was generated from.
%matplotlib inline
import pandas as pd
points = pd.DataFrame(data, columns=["x1", "x2"])
points.plot.scatter("x1", "x2")

We can see here that these clusters are very distinct. This is a very good situation to use k-means clustering in and it will give a useful result.
We initialise the KMeans object with the number of clusters we are looking for (n_clusters is a hyperparameter). This is important as k-means requires this decision to be made up-front. There are some clustering algorithms which can attempt to calculate the number of clusters for you but when using k-means you need to make that assessment yourself.
There are other hyperparameters that can be passed to KMeans which are explained in full in the documentation.
Passing the data you want to fit to the fit() method will then actually perform the algormithm. You can pass in nested lists, numpy arrays (as long as they have the shape $(N_{samples}, N_{features})$) or pandas DataFrames.
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=4, n_init="auto").fit(points)
Now that we have calculated the cluster centres, we can use the cluster_centers_ data attribute of our model to see what clusters it has decided on.
cluster_centers = pd.DataFrame(kmeans.cluster_centers_, columns=["x1", "x2"])
cluster_centers
Comparing these $x$ and $y$ values against the plot above, we see that it seems to have placed the centres in the correct location. It's better though to be able to see this directly, so let's plot the centres on top of the original data.
ax = points.plot.scatter("x1", "x2")
cluster_centers.plot.scatter("x1", "x2", ax=ax, c="red", s=200, marker="x")

The other piece of data that we can retrieve from the model is which cluster it assigned to each data point. This is available as the labels_ data attribute and is an array with 500 entries, each being a number between 0 and 3. We can use it to colour our plot to see the clusters emerge.
points.plot.scatter("x1", "x2", c=kmeans.labels_, colormap="Dark2", colorbar=False)

Exercise 1¶
- Run the above example again but try setting different
random_statevalues when creating the blobs. What happens when the generated clusters overlap a lot?
Exercise 2¶
Using the data provided by
sklearn.datasets.load_iris, perform the clustering on the data.Tip: load the data into a
DataFramewith:from sklearn.datasets import load_iris iris = pd.DataFrame(load_iris().data, columns=load_iris().feature_names)
Tip: Note that the Iris dataset has four input dimensions. You can pass all four columns into the k-means clustering algorithm with
kmeans.fit(iris)
Exercise 3 (optional)¶
Another data attribute of the model is
inertia_which gives you the sum of the squared distances of data points to their closest cluster center. It is this attribute which the algorithm uses to decide whether it has converged. In general a smaller number represents a better fit.Write a loop which performs the k-means fit over the blob-generated data with the number of clusters varying from 2 up to 7. For each of these fits, extract the value of the
inertia_attribute and draw a plot of inertia against number of clusters.
Other clustering algorithms¶
There are different clustering algorithms beyond k-means. scikit-learn come with many and you can see them all in the documentation.
k-means famously has problems with clusters which are elongated in some direction as it assumes sphericity. Look at the fourth row of this image (where the k-means we are using is the one in the first column):
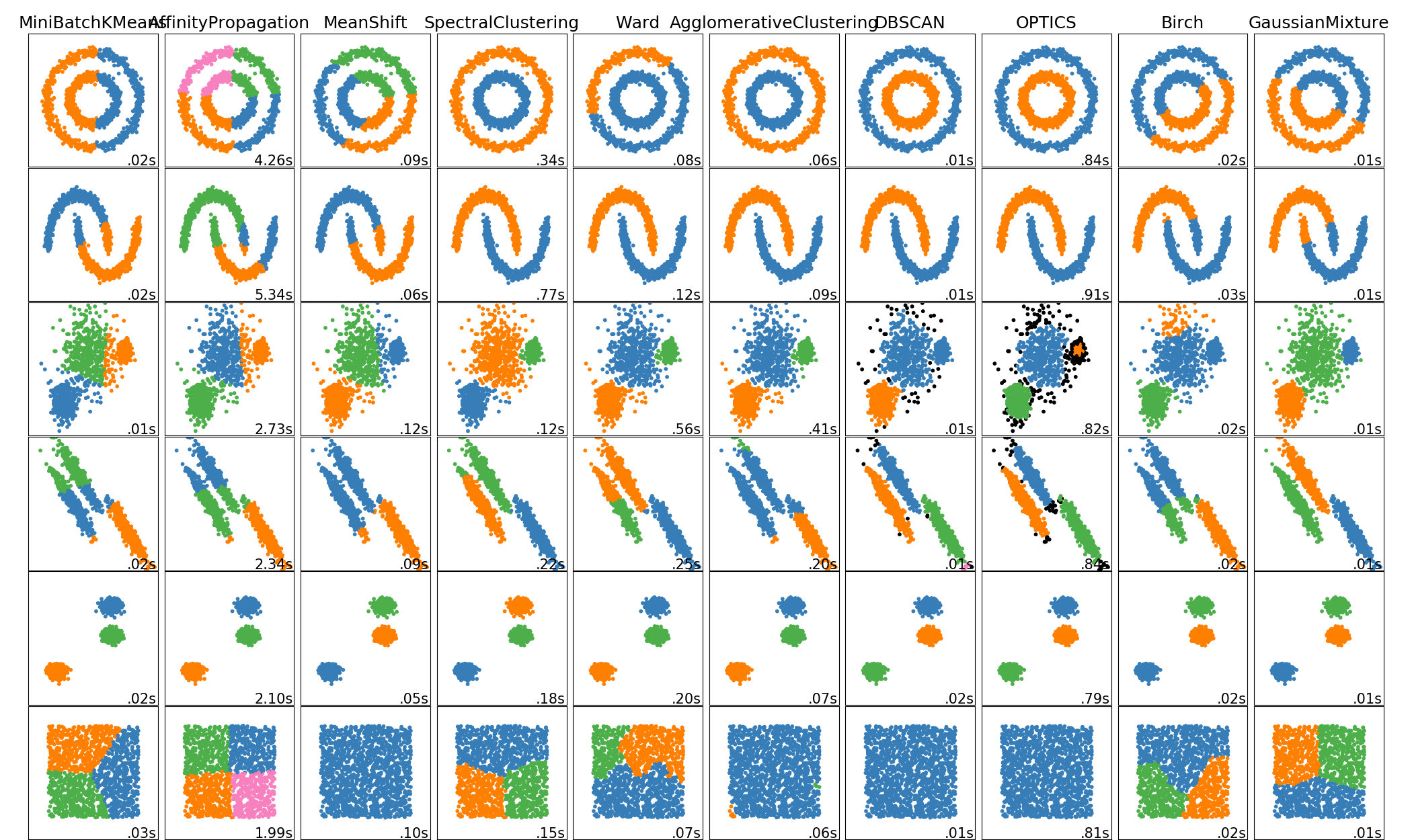
It has failed to cluster the three groups in the way that we as humans would have done. Other algorithms (such as DBSCAN) perform better in that situation.
One solution with k-means is to transform the data in some way to make it more spherical and then apply clustering. This pre-processing can be done with something like PCA.
The other type of preprocessing you may like to do is to manually reparameterise the data. For example, the first row has two circular clusters which share a centre. Since k-means works on cluster-centres it can't tell them apart. However, if that data was reparameterised into $(r, \theta)$ then the two clusters would become distinct and k-means would work well.
This is why it's always worth plotting your data and deciding how to process it before throwing machine learning algorithms at it.